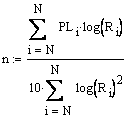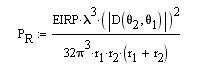|
Multiple methods were applied and analyzed in the creation of the propagation model for phase 1. Section one explains the implemented model used to predict the received power strengths. Section two describes other methods that were tested and researched, and why they were not used in the final model. | ||||||||||||||||||||||||||||||||||||
| 1. Propagation Model | ||||||||||||||||||||||||||||||||||||
| Estimating Antenna Gain | ||||||||||||||||||||||||||||||||||||
|
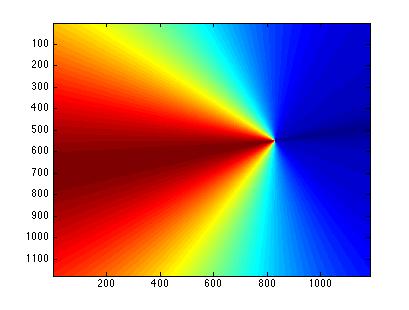
The power received at any particular location is dependent on the orientation from the transmitting antenna. Most cellular base stations have a half power bandwidth of 120 degrees. This means that the power transmitted by the antenna is halved at an orientation of 60 degrees from the antennas peak direction. In addition to half power bandwidth, most base station antennas have a front-to-back gain ratio of at least 25dB [1]. These specifications were used to create a vector of angles and a vector of expected gains. MatLab's polyfit function was used to interpolate between these vectors and create a fourth degree polynomial for the gain as a function of azimuth. x = [0 2 20 60 120 180]; % angles in degrees The fourth degree polynomial response corresponding to the base stations direction and orientation is shown in Figure 1.
Path Loss and Path Loss Exponent | ||||||||||||||||||||||||||||||||||||
|
The Friis free-space link budget formula was used as a foundation for estimating the received power at a distance r from the transmitting antenna. The log form of the equation is given as:
The variable PL represents path loss and includes the loss due to distance separation and also diffraction, terrain, etc. The path loss exponent model combines all these losses and attaches them as an exponent, n, to the distance loss:
The value of n is always chosen so as to minimize the mean square error between the measured path loss and the estimated path loss. This results in n being defined as:
The path loss at each given location was calculated with the power received data for Cell_Info_A through D using the link budget equation. Each path loss value was then separated into 1 of 17 groups corresponding to each measured locations environment or "clutter" value. A path loss exponent, n, was then calculated for each of the 17 different clutter groups. A table of the calculated path loss exponents is shown below.
For clutter values that did not have received signal strengths, the n path loss exponent values were chosen to match a similar clutter value that did. For example, the clutter value "sea" was chosen to have the same path loss exponent as "inland water" since there were no received power levels to estimate the path loss exponent for the sea. The estimated received signal power for maps A through D using this model are analyzed here. The file pReceivedModel.m calculates the gain as a function of azimuth, the distance from each cell to TX, and the estimated path loss for the maps A-D. These values are all stored in matrices to act as easy look up tables. The file also calculates the N values and stores the estimated power received in the structure field variables(i).myguess. | ||||||||||||||||||||||||||||||||||||
| 2. Rejected Propagation Models | ||||||||||||||||||||||||||||||||||||
| Diffraction | ||||||||||||||||||||||||||||||||||||
|
Terrain diffraction was estimated using the Geometrical Theory of Diffraction (GTD) formula in which any obstruction is treated as a perfect electrical conducting wedge [2]. A linear (y=mx+b) function was calculated to represent a line-of-site path from the top of the transmitter to the top of the receiver. The function findpath.m was written to find and return the cell locations that fell in a straight line from the receiver to the base station. Then, storeDiffraction.m looped through each one of the cell locations in the path from the transmitter to the receiver and checked to see if the terrain blocked the line-of-sight (y=mx+b) path. If terrain blocked the line-of-sight path then storeDiffraction.m took the tallest obstruction and estimated the power received using the GTD formula. This method was first tested with Cell_Info_A. The function was set to loop through the received power locations and determine if there was an LOS obstruction between the TX and RX. If there was, the received power was estimated according to GTD. The remaining received powers that did not contain an LOS obstruction were used to calculate a path loss exponent, n, based on the location clutter (just like Section 1). Which, if implemented correctly, should cause the path loss exponent values to be a better representation of the clutter zones. Comparing Cell_Info_A with Team1_Guess_A resulted in: Site Cell_Info_A, mean of +3.09 dB, std dev of 7.83 dB The diffraction and path loss exponent models combined have a lower RPS than just the path loss exponent here; however, the code took twenty minutes to run on 14,994 cells. Since the compared locations for maps E-H are unknown it means the model would have to analyze more than 1 million cells for obstruction. This would result in days of computation and thus the diffraction model was dropped. | ||||||||||||||||||||||||||||||||||||
| Blockage Loss | ||||||||||||||||||||||||||||||||||||
|
The next proposed model was to use the function findpath.m to count the number of different clutter zones the signal passes through from the transmitter to receiver. Using these values a mean square error blockage loss can be calculated for each clutter zone. This method can best be described by the following equation [3]:
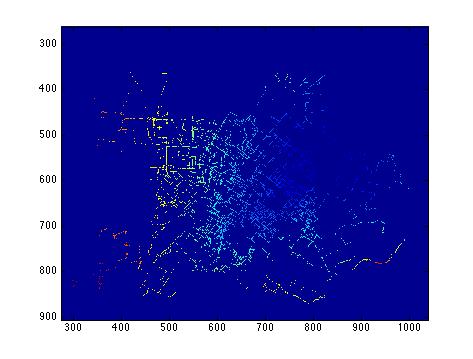
To minimize the degrees of freedom, only the four most common clutter zones between the TX and RX were used to create a blockage loss: Urban, Cropland, Parks, and Res. low vegetation. The biggest problem with this method is best shown in the following graphic:
The number of clutter zones measured far away from the TX is much greater than the number of clutter zones near the TX so the path loss increases. This makes intuitive sense because as a signal propagates through more blockage you expect the signal to decrease. However, this does not adequately estimate bloackage close to the TX. So, the blockage losses where then calculated based on the distance from the TX. From this point on the clutter values became more of guessing game since some matrices would be non-invertable. In addition, it was pointless to use blockage loss if the RX had a LOS path from the TX (i.e. on a hill). These discrepancies threw off the clutter values at varying distances and increased the squared error, so the model was dropped. | ||||||||||||||||||||||||||||||||||||
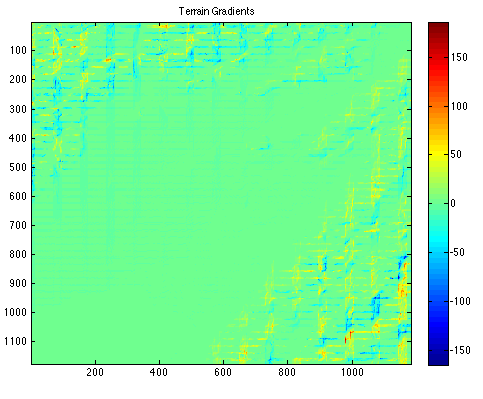
| Terrain Gradients | ||||||||||||||||||||||||||||||||||||
|
This model attempted to find diffraction and wedge points based on the areas terrain gradient. The difference of the terrain model was taken both horizontally and vertically to come up with an estimate for the total terrain change for each cell. The code that produces the gradient is shown below: [nrows ncols] = size(Cell_Info_A.data);The plot below is the output, total_gradient:
Comparing this graph to the terrain given in Cell_Info_A you can see that the gradient appropriately finds areas where there are extreme terrain changes. This method was used to try to decrease the number of diffraction calculations by only calculating diffraction on areas where the terrain change was < -10. The only problem with this model approach is that there were not enough received power data points in areas of high terrain to prove its usefulness, and still required ~100,000 diffraction calculations. [1] http://www.winncom.com/products/category/910/list.html [2] Durgin, Gregory D., The Practical Behavior of Various Edge Diffraction Formulas [3] G.D. Durgin, T.S. Rappaport, H. Xu. "Measurements and Models for Radio Path Loss and Penetration Loss In and Around Homes and Trees at 5.85-GHz". IEEE Transactions on Communications, vol 46, no 11, November 1998, pp. 1484-1496 |